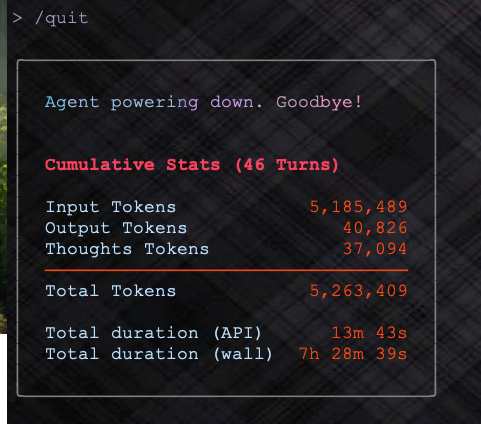
如何应对 DeepSeek 的 64K 上下文限制?
cline + deepseek 低成本AI 编程的一些体验总结
intro
在使用大善人的 gemini 之前(现在天天用),我用了一段时间的 cline + deepseek 来开发了一些软件(没有用公司的cursor的原因是我想体验一下这个组合,也避免一些问题)。
今天看到这个问题 有什么办法在deepseek的两段对话间传递信息吗? 有一些想说的,就来做个体验总结。
Part2
前段时间,用了一段时间 cline + deepseek ,也碰到这种问题(受限于 64K上下文),我总结一下我的感受和一些方法。
省流: 事前、事中、事后多让 AI 写总结文档。人为拆分任务,确保每次会话聚焦特定任务。
合理拆分任务
可以在开始做之前就使用AI 描述你的整体需求,拆分合适的开发计划。把代码实现拆解为多个阶段,每个阶段的主要解决的问题。可以让 AI 把这些计划总结出来,比如把总体产品文档总结为 product.md ,把整体技术架构和开发计划总结为 tech.md ,把某个特定领域的开发计划总结为 tech.xx.md 。提供不同颗粒度的文档,这样后续新对话前时候,可以手动让 AI 先读取这些总结过的文档,知道我们要干什么,让他做好准备。
当然这里的文档要仔细甄别,甚至上手调整,AI 的规划文档里面多了一个技术名词,可能就会导致后面生成大量无关的代码。
聚焦对话任务
聚焦对话任务,有两个好处,1. 容易评估会话的结果,2. 丢弃会话成本低。 不论是实现第一次的初始化,还是实现某次的 Bug 修改,都可以只让它完成这次任务就行。完成了,基本合格,就可以提交保存了。这样再下一次新会话的时候,如果聊的不好,完全可以删掉重来。一次对话,读取合适的上下文文档和代码,完成某个小点就可以了。
比如同一个功能,可以先让他根据产品需求设计后端的模块和接口文档,这一份文档可以分别在两个会话里面,分别去实现后端接口,和前端代码。而如果糅合在一个会话里面,往往就超过上下文限制,导致无法产出可用结果。
另外,在实践过程中,有时候在会话中突然聊起别的事情,还容易把AI 搞混了。
减少任务大小
之前碰到调整一些历史代码的场景,合理控制代码文件大小,也是一个有效的手段。对于那种把 html / js/css 都写到同一个文件的代码来说。用 deepseek 这样的上下文的 api 是很困难的,说不上两句或者没输出完整代码,就超了64K。
可以手动或者让 AI 来做这样的模块化分割,减少同一个文件的内容/知识。合理结构的代码目录和适当的代码分割也更容易满足上面的第二步的要求。
需要注意的时,让AI 生成代码的时候也这么做,比如最开始后端接口只在一个 server/index.ts ,稍不注意他可能每一个接口都塞到这个里面来了。需要在会话开始时,指导它要将某个领域的接口写入到单独的文件里面来。
及时总结
如果会话的过程中,发现改动计划调整比较大,可能64K 上下文不够用的时候,可以及时停止代码生成,反而要求它总结当前的改动计划,调整哪个文件的哪个地方。挽救一下沉没成本。
下一次会话的时候,可以阅读这个临时的改动计划文档,先改第一步。改动完成之后,再开启新会话,读取这个改动计划文档,告诉他第一步已经改完了,请他按第二步调整。如此如此。
一些其他的使用体验
细碎的文件名 在一些大型项目里面,分层比较多,导致代码可能有十多个 user.go 或者 user.py, 很难选择出哪一个 user.go 是我们要让AI 参考的。
我的建议是把层次写到文件名上面来。 user_dao.go 和 user_controller.go /user_service.go / user_api.go / user_handler.go / user_rpc.go 这样可能就更好引用了。
一个月 ¥50 元的 AI 成本
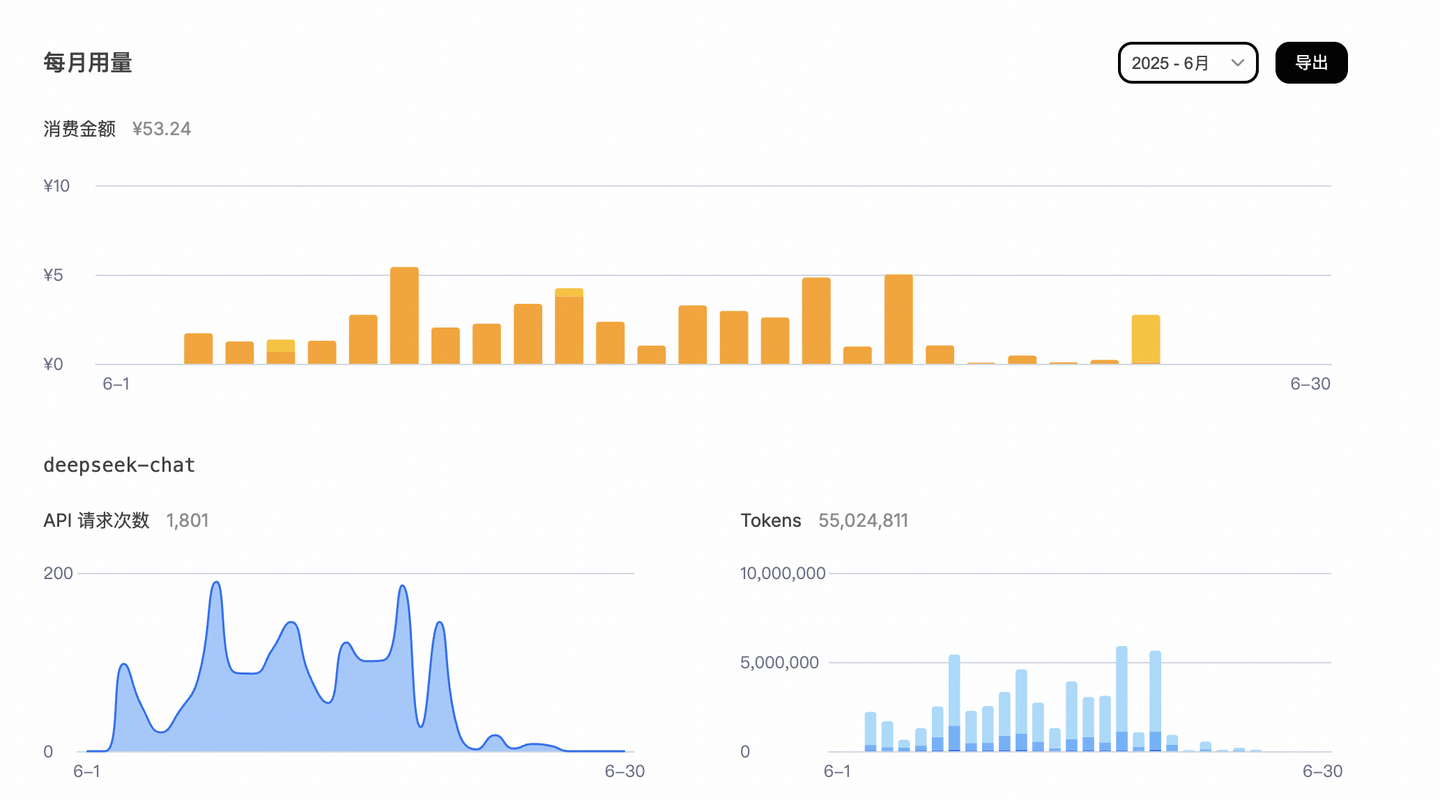
当然,在用上了 gemini 之后,我已经不再使用这套方案了,直到下一次用不了 gemini 为止。