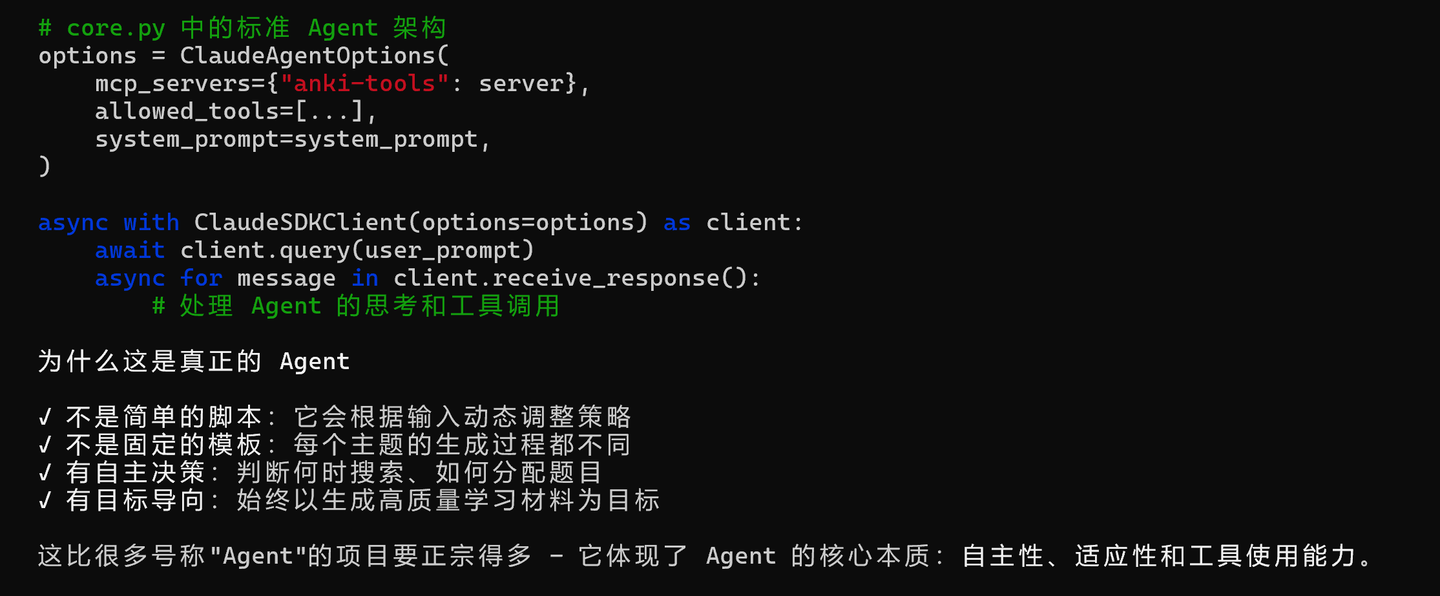
Harness Engineering 学习调研
本文包含 AI 辅助创作内容 目录 背景 Harness Engineering 解决什么问题? Prompt Engineering 解决什么问题? Context Engineering 解决什么问题? Harness Engineering 解决什么问题? Agent 可靠执行需要解决的问题 可观测性 治理与安全 Memory 管理 测评与评估以及训练 Agent 测评体系的三个层次 评估基础设施 Evals 驱动的提示词优化(轻量级训练) 评估与训练的飞轮(Eval-Train Loop) Judge 机制的选择 所以最后,Harness Engineering 是什么呢? 背景 昨天有一个二面的面试,我感觉她说的挺有道理的,有许多是我之前做过但是没有真正认真想过的。主要内容是关于如何做一个类 Claw 的产品,以及做这种类 Claw 产品的核心竞争力。 其中就涉及到「Harness Engineering」,因此这篇文章,我就从初学者入手,做一些资料收集和总结。后续我会挑选一个之前实现的 Agent 来做,再写另外一篇实践的文章。 Harness Engineering 解决什么问题? 介绍 Harness Engineering 之前,我们看看它试图解决什么问题。 在这之前,我们还可以更先看看 Prompt Engineering 和 Context Engineering 解决了什么问题。 Prompt Engineering 解决什么问题? 核心问题:如何正确地向 AI 下达指令(意图表达与对齐) 痛点:早期大模型(LLM)虽然聪明,但往往是非确定性的。如果提问方式不对,它会输出不符合预期的结果。 解决方案:通过精心设计输入文本(如 Few-shot、Chain-of-Thought、角色扮演等技巧),引导模型按照人类的期望进行推理和生成。 作用范围:单次交互(Single Interaction)。它关注的是”我们该怎么问”(What should be asked)。 主要关注一次 LLM 调用的提示词编写。 Context Engineering 解决什么问题?...